前言
LinkedHashMap是面试中比较容易问到的集合之一。本篇文章主要通过分析LinkedHashMap的源码,更深入的了解LinkedHashMap,以及对比LinkedHashMap在JDK1.8和JDK1.7的不同。
本文基于jdk1.8
LinkedHashMap简介
LinkedHashMap类结构
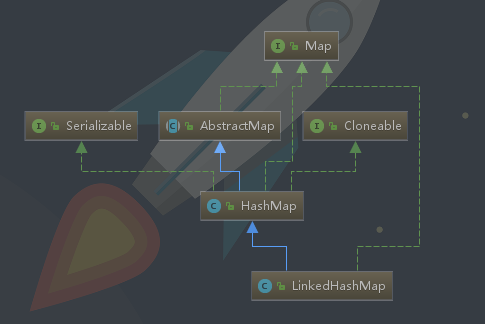
可以从上图看出,LinkedHashMap继承HashMap,实现了Map接口。
LinkedHashMap特点
- LinkedHashMap非线程安全,在多线程中保证线程安全的解决方法:使用
Map map = Collections.synchronizedMap(new LinkedHashMap());。 - LinkedHashMap底层是数组和双向链表组成的。
- LinkedHashMap的key和value都允许为null。
- LinkedHashMap的数据存储是有序的。
- LinkedHashMap继承自HashMap,所以HashMap的特点,除了输出无序,其他LinkedHashMap都有。
LinkedHashMap提供的API
| 方法名 | 方法解释 |
|---|---|
| clear() | 从LinkedHashMap中移除所有映射。 |
| containsValue(Object value) | LinkedHashMap中匹配到指定值,则返回true。 |
| entrySet() | 返回LinkedHashMap中包含的映射的Set。 |
| forEach(BiConsumer<? super K, ? super V> action) | 将给定操作(BiConsumer)应用于LinkedHashMap的每一个元素,直到处理完所有数据或操作抛出异常为止。 |
| get(Object key) | 返回指定key映射到的值;如果LinkedHashMap中不包含key的映射,则返回null。 |
| getOrDefault(Object key, V defaultValue) | 返回指定key映射到的值;如果LinkedHashMap中不包含key的映射,则返回defaultValue。 |
| keySet() | 返回LinkedHashMap中包含的key的Set。 |
| removeEldestEntry(Map.Entry<K,V> eldest) | 是否移除LinkedHashMap中最年长的节点。 |
| replaceAll(BiFunction<? super K, ? super V, ? extends V> function) | 对LinkedHashMap调用给定函数的结果替换每个数据的value,直到处理完所有数据或者该函数抛出异常。 |
| values() | 返回LinkedHashMap中包含的value的集合。 |
LinkedHashMap源码
LinkedHashMap成员变量
1 | /** |
LinkedHashMap内部类
Entry
1 | /** |
LinkedHashMap构造函数
LinkedHashMap有5个构造方法,与HashMap的很相似,就是多了一个accessOrder控制输出顺序。
1 | public LinkedHashMap() { |
###LinkedHashMap重要方法解析
put(K key, V value)
LinkedHashMap没有重写HashMap的put方法,但是重写了newNode方法,HashMap的putVal方法会调用newNode方法。我们一起看一下:
HashMap#newNode:
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) { |
LinkedHashMap#newNode:
1 | Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { |
linkNodeLast:
1 | private void linkNodeLast(LinkedHashMap.Entry<K,V> p) { |
HashMap预留给LinkedHashMap的方法
afterNodeAccess(Node<K,V> e):
1 | // 将节点移到最后 |
afterNodeInsertion:
1 | // 回调函数,新节点插入之后回调,根据evict和判断是否需要删除最老插入的节点 |
get(Object key)
1 | public V get(Object key) { |
getOrDefault(Object key, V defaultValue)
1 | public V getOrDefault(Object key, V defaultValue) { |
remove(Object key)
LinkedHashMap也没有重写HashMap的remove方法。
HashMap预留给LinkedHashMap的方法
afterNodeRemoval:
1 | // 删除节点的同时,将节点从双向链表中删除 |
entrySet()
1 | public Set<Map.Entry<K,V>> entrySet() { |
LinkedEntrySet
1
2
3
4
5
6final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
// 省略部分方法
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
}LinkedEntryIterator
1
2
3
4final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}LinkedHashIterator
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48abstract class LinkedHashIterator {
// 下一个节点
LinkedHashMap.Entry<K,V> next;
// 当前节点
LinkedHashMap.Entry<K,V> current;
// 预期的操作次数
int expectedModCount;
LinkedHashIterator() {
// 初始化时,next为LinkedHashMap内部维护的双向链表的表头
next = head;
// 记录当前modCount,以满足fail-fast
expectedModCount = modCount;
// 当前节点为null
current = null;
}
// 判断是否还有下一个
public final boolean hasNext() {
// 就是判断下一个是否为null
return next != null;
}
// 可以看出,迭代LinkedHashMap是从内部维护的双链表的表头开始循环输出
// 初始LinkedHashMap的容量对遍历没有影响
final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
总结
LinkedHashMap相对于HashMap的源码比起来简单很多,只是重写了部分方法。不过由于其内部维护了一个双向链表,所以在数据结构上比HashMap要复杂一点。
欢迎关注博主其他的文章。

